


Filtering & Closing Pull Requests on GitHub using the API
Hi everyone! 👋 In this post, I am going to show you how you can use the GitHub API to query Pull Requests, check the content of a PR and close it.
The motivation for this project came from my personal website. I introduced static comments on the website using Staticman and only after a day or two, got bombarded with spam. I hadn’t enabled Akismet or any honey pot field so it was kinda expected. However, this resulted in me getting 200+ PRs on GitHub for bogus comments which were mainly advertisements for amoxicillin (this was also the first time I found out how famous this medicine is).
I was in no mood for going through the PRs manually so I decided to write a short script which went through them on my behalf and closed the PRs which mentioned certain keywords.
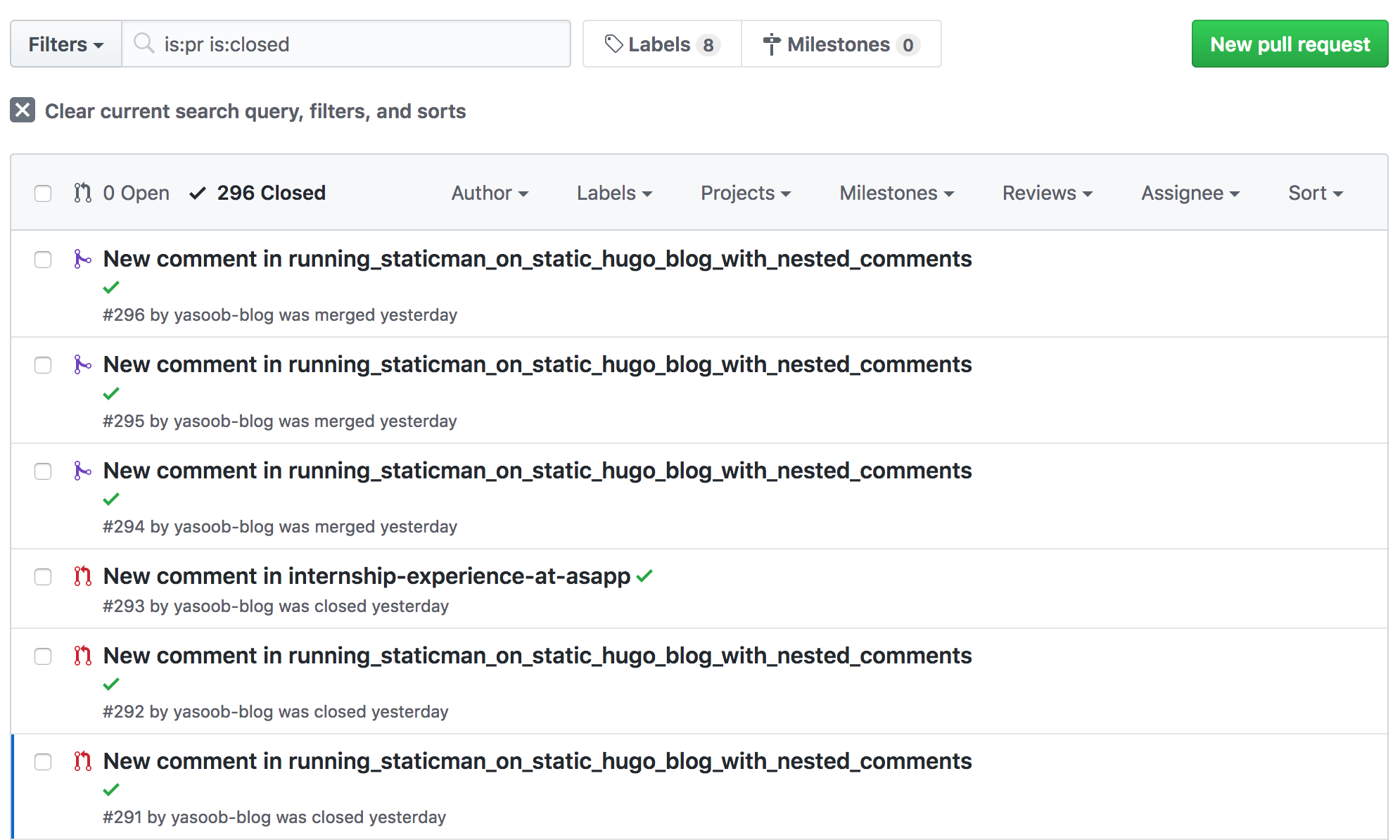
You can see the different PRs opened by staticman. Most of these are spam:
For this project, I decided to use PyGithub library. It is super easy to install it using pip:
pip install pygithub
Now we can go ahead and log in to GitHub using PyGithub. Write the following code in a github_clean.py file:
from github import Github
import argparse
def parse_arguments():
"""
Parses arguments
"""
parser = argparse.ArgumentParser()
parser.add_argument('-u', '--username',
required=True, help="GitHub username")
parser.add_argument('-p', '--password',
required=True, help="GitHub password")
parser.add_argument('-r', '--repository',
required=True, help="repository name")
parsed_args = parser.parse_args()
if "/" not in parsed_args.repository:
logging.error("repo name should also contain username like: username/repo_name")
sys.exit()
return parsed_args
def main():
args = parse_arguments()
g = Github(args.username, args.password)
if __name__ == '__main__':
main()
So far I am just using argparse to accept and parse the command line arguments and then using the arguments to create a Github object.
You will be passing in three arguments:
- Your GitHub username
- Your GitHub password
- The repo you want to work with
Next step is to figure out how to loop through all the pull requests and check if their body contains any “spam” words:
repo = g.get_repo(args.repository)
issues = repo.get_issues()
page_num = 0
while True:
issue_page = issues.get_page(page_num)
if issue_page == []:
break
for issue in issue_page:
# Do something with the individual issue
if spam_word in issue.raw_data['body'].lower():
print("Contains spam word!!")
First, we query GitHub for a specific repo using g.get_repo and then we query for issues for that repo using repo.get_issues. It is important to note that all PRs are registered as issues as well so querying for issues will return pull requests as well. GitHub returns a paginated result so we just continue asking for successive issues in a while loop until we get an empty page.
We can check the body of an issue (PR) using issue.raw_data[‘body’]. Two important pieces are missing from the above code. One is the spam_word variable and another is some sort of a mechanism to close an issue.
For the spam_word, I took a look at some issues and created a list of some pretty frequent spam words. This is the list I came up with:
spam_words = ["buy", "amoxi", "order", "tablets",
"pills", "cheap", "viagra", "forex", "cafergot",
"kamagra", "hacker", "python training"]
Add this list at the top of your github_clean.py file and modify the if statement like this:
closed = False
if any(spam_word in issue.raw_data['body'].lower() for spam_word in spam_words):
issue.edit(state="closed")
closed = True
print(f"{issue.number}, closed: {closed}")
With this final snippet of code, we have everything we need. My favourite function in this code snippet is any. It checks if any of the elements being passed in as part of the argument is True.
This is what your whole file should look like:
import argparse
import sys
import re
import logging
from github import Github
spam_words = ["buy", "amoxi", "order", "tablets",
"pills", "cheap", "viagra", "forex", "cafergot",
"kamagra", "hacker", "python training"]
logging.basicConfig(level=logging.INFO)
def parse_arguments():
"""
Parses arguments
"""
parser = argparse.ArgumentParser()
parser.add_argument('-u', '--username',
required=True, help="GitHub username")
parser.add_argument('-p', '--password',
required=True, help="GitHub password")
parser.add_argument('-r', '--repository',
required=True, help="repository name")
parsed_args = parser.parse_args()
if "/" not in parsed_args.repository:
logging.error("repo name should also contain username like: username/repo_name")
sys.exit()
return parsed_args
def process_issue(issue):
"""
Processes each issue and closes it
based on the spam_words list
"""
closed = False
if any(bad_word in issue.raw_data['body'].lower() for bad_word in words):
issue.edit(state="closed")
closed = True
return closed
def main():
"""
Coordinates the flow of the whole program
"""
args = parse_arguments()
g = Github(args.username, args.password)
logging.info("successfully logged in")
repo = g.get_repo(args.repository)
logging.info("getting issues list")
issues = repo.get_issues()
page_num = 0
while True:
issue_page = issues.get_page(page_num)
if issue_page == []:
logging.info("No more issues to process")
break
for issue in issue_page:
closed = process_issue(issue)
logging.info(f"{issue.number}, closed: {closed}")
page_num += 1
if __name__ == '__main__':
main()
I just added a couple of different things to this script, like the logging. If you want, you can create a new command-line argument and use that to control the log level. It isn’t really useful here because we don’t have a lot of different log levels.
Now if you run this script you should see something similar to this:
INFO:root:successfully logged in
INFO:root:getting issues list
INFO:root:No more issues to process
It doesn’t process anything in this run because I have already run this script once and there are no more spam issues left.
So there you go! I hope you had fun making this! If you have any questions/comments/suggestions please let me know in the comments below! See you in the next post 🙂 ♥️
✍️ Comments
Thank you!
Your comment has been submitted and will be published once it has been approved. 😊
OK