


Reverse Engineering Facebook API: Private Video Downloader
Welcome back! This is the third post in the reverse engineering series. The first post was reverse engineering Soundcloud API and the second one was reverse engineering Facebook API to download public videos. In this post we will take a look at downloading private videos. We will reverse engineer the API calls made by Facebook and will try to figure out how we can download videos in the HD format (when available).
Step 1: Recon
The very first step is to open up a private video in an incognito tab just to make sure we can not access it without logging it. This should be the response from Facebook:
This confirms that we can not access the video without logging in. Sometimes this is pretty obvious but it doesn’t hurt to check.
We know of our first step. It is to figure out a way to log-into Facebook using Python. Only after that can we access the video. Let’s login using the browser and check what information is required to log-in.
I won’t go into much detail for this step. The gist is that while logging in, the desktop website and the mobile website require roughly the same POST parameters but interestingly if you log-in using the mobile website you don’t have to supply a lot of additional information which the desktop website requires. You can get away with doing a POST request to the following URL with your username and password:
https://m.facebook.com/login.php
We will later see that the subsequent API requests will require a fb_dtsg parameter. The value of this parameter is embedded in the HTML response and can easily be extracted using regular expressions or a DOM parsing library.
Let’s continue exploring the website and the video API and see what we can find.
Just like what we did in the last post, open up the video, monitor the XHR requests in the Developer Tools and search for the MP4 request.
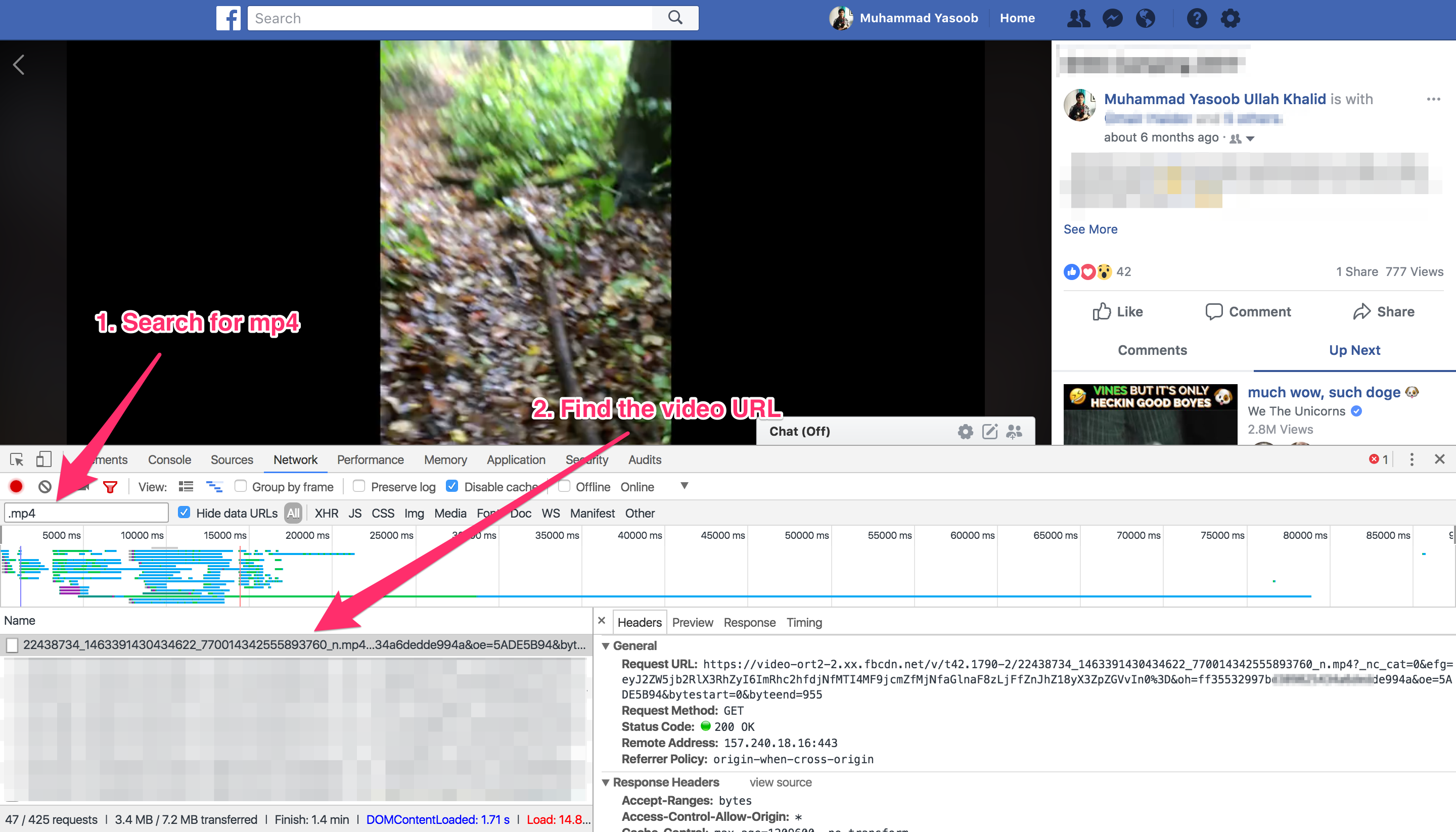
Next step is to figure out where the MP4 link is coming from. I tried searching the original HTML page but couldn’t find the link. This means that Facebook is using an XHR API request to get the URL from the server. We need to search through all of the XHR API requests and check their responses for the video URL. I did just that and the response of the third API request contained the MP4 link:
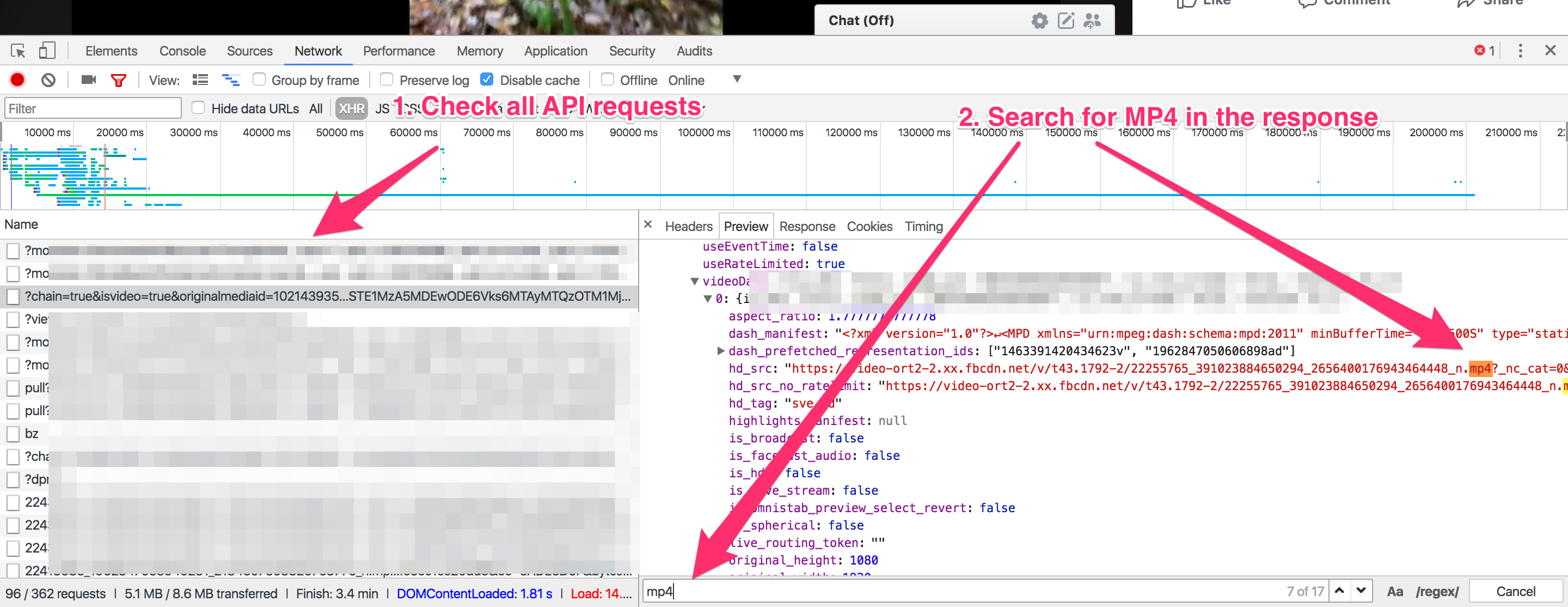
The API request was a POST request and the url was:
https://www.facebook.com/video/tahoe/async/10114393524323267/?chain=true&isvideo=true&originalmediaid=10214393524262467&playerorigin=permalink&playersuborigin=tahoe&ispermalink=true&numcopyrightmatchedvideoplayedconsecutively=0&storyidentifier=DzpfSTE1MzA5MDEwODE6Vks6MTAyMTQzOTMNjE4Njc&dpr=2
I tried to deconstruct the URL. The major dynamic parts of the URL seem to be the originalmediaid and _storyidentifier. _I searched the original HTML page and found that both of these were there in the original video page. We also need to figure out the POST data sent with this request. These are the parameters which were sent:
__user: <---redacted-->
__a: 1
__dyn: <---redacted-->
__req: 3
__be: 1
__pc: PHASED:DEFAULT
__rev: <---redacted-->
fb_dtsg: <---redacted-->
jazoest: <---redacted-->
__spin_r: <---redacted-->
__spin_b: <---redacted-->
__spin_t: <---redacted-->
I have redacted most of the stuff so that my personal information is not leaked. But you get the idea. I again searched the HTML page and was able to find most of the information in the page. There was certain information which was not in the HTML page like _jazoest _but as we move along you will see that we don’t really need it to download the video. We can simply send an empty string in its place.
It seems like we have all the pieces we need to download a video. Here is an outline:
- Open the Video after logging in
- Search for the parameters in the HTML response to craft the API url
- Open the API url with the required POST parameters
- Search for hd_src or sd_src in the response of the API request
Now lets create a script to automate these tasks for us.
Step 2: Automate it
The very first step is to figure out how the login takes place. In the recon phase I mentioned that you can easily log-in using the mobile website. We will do exactly that. We will log-in using the mobile website and then open the homepage using the authenticated cookies so that we can extract the fb_dtsg parameter from the homepage for subsequent requests.
import requests
import re
import urllib.parse
email = ""
password = ""
session = requests.session()
session.headers.update({
'User-Agent': 'Mozilla/5.0 (X11; Linux i686; rv:39.0) Gecko/20100101 Firefox/39.0'
})
response = session.get('https://m.facebook.com')
response = session.post('https://m.facebook.com/login.php', data={
'email': email,
'pass': password
}, allow_redirects=False)
Replace the email and password variable with your email and password and this script should log you in. How do we know whether we have successfully logged in? We can check for the presence of ‘c_user’ key in the cookies. If it exists then the login has been successful.
Let’s check that and extract the fb_dtsg from the homepage. While we are at that let’s extract the user_id from the cookies as well because we will need it later.
if 'c_user' in response.cookies:
# login was successful
homepage_resp = session.get('https://m.facebook.com/home.php')
fb_dtsg = re.search('name="fb_dtsg" value="(.+?)"', homepage_resp.text).group(1)
user_id = response.cookies['c_user']
So now we need to open up the video page, extract all of the required API POST arguments from it and do the POST request.
if 'c_user' in response.cookies:
# login was successful
homepage_resp = session.get('https://m.facebook.com/home.php')
fb_dtsg = re.search('name="fb_dtsg" value="(.+?)"', homepage_resp.text).group(1)
user_id = response.cookies['c_user']
video_url = "https://www.facebook.com/username/videos/101214393524261127/"
video_id = re.search('videos/(.+?)/', video_url).group(1)
video_page = session.get(video_url)
identifier = re.search('ref=tahoe","(.+?)"', video_page.text).group(1)
final_url = "https://www.facebook.com/video/tahoe/async/{0}/?chain=true&isvideo=true&originalmediaid={0}&playerorigin=permalink&playersuborigin=tahoe&ispermalink=true&numcopyrightmatchedvideoplayedconsecutively=0&storyidentifier={1}&dpr=2".format(video_id,identifier)
data = {'__user': user_id,
'__a': '',
'__dyn': '',
'__req': '',
'__be': '',
'__pc': '',
'__rev': '',
'fb_dtsg': fb_dtsg,
'jazoest': '',
'__spin_r': '',
'__spin_b': '',
'__spin_t': '',
}
api_call = session.post(final_url, data=data)
try:
final_video_url = re.search('hd_src":"(.+?)",', api_call.text).group(1)
except AttributeError:
final_video_url = re.search('sd_src":"(.+?)"', api_call.text).group(1)
print(final_video_url)
You might be wondering what the data dictionary is doing and why there are a lot of keys with empty values. Like I said during the recon process, I tried making successful POST requests using the minimum amount of data. As it turns out Facebook only cares about fb_dtsg and the __user key. You can let everything else be an empty string. Make sure that you do send these keys with the request though. It doesn’t work if the key is entirely absent.
At the very end of the script we first search for the HD source and then the SD source of the video. If HD source is found we output that and if not then we output the SD source.
Our final script looks something like this:
import requests
import re
import urllib.parse
import sys
email = sys.argv[-2]
password = sys.argv[-1]
print("Email: "+email)
print("Pass: "+password)
session = requests.session()
session.headers.update({
'User-Agent': 'Mozilla/5.0 (X11; Linux i686; rv:39.0) Gecko/20100101 Firefox/39.0'
})
response = session.get('https://m.facebook.com')
response = session.post('https://m.facebook.com/login.php', data={
'email': email,
'pass': password
}, allow_redirects=False)
if 'c_user' in response.cookies:
# login was successful
homepage_resp = session.get('https://m.facebook.com/home.php')
fb_dtsg = re.search('name="fb_dtsg" value="(.+?)"', homepage_resp.text).group(1)
user_id = response.cookies['c_user']
video_url = sys.argv[-3]
print("Video url: "+video_url)
video_id = re.search('videos/(.+?)/', video_url).group(1)
video_page = session.get(video_url)
identifier = re.search('ref=tahoe","(.+?)"', video_page.text).group(1)
final_url = "https://www.facebook.com/video/tahoe/async/{0}/?chain=true&isvideo=true&originalmediaid={0}&playerorigin=permalink&playersuborigin=tahoe&ispermalink=true&numcopyrightmatchedvideoplayedconsecutively=0&storyidentifier={1}&dpr=2".format(video_id,identifier)
data = {'__user': user_id,
'__a': '',
'__dyn': '',
'__req': '',
'__be': '',
'__pc': '',
'__rev': '',
'fb_dtsg': fb_dtsg,
'jazoest': '',
'__spin_r': '',
'__spin_b': '',
'__spin_t': '',
}
api_call = session.post(final_url, data=data)
try:
final_video_url = re.search('hd_src":"(.+?)",', api_call.text).group(1)
except AttributeError:
final_video_url = re.search('sd_src":"(.+?)"', api_call.text).group(1)
print(final_video_url.replace('\\',''))
I made a couple of changes to the script. I used sys.argv to get video_url, email and password from the command line. You can hardcore your username and password if you want.
Save the above file as facebook_downloader.py and run it like this:
$ python facebook_downloader.py video_url email password
Replace video_url with the actual video url like this https://www.facebook.com/username/videos/101214393524261127/ and replace the email and password with your actual email and password.
After running this script, it will output the source url of the video to the terminal. You can open the URL in your browser and from there you should be able to right-click and download the video easily.
I hope you guys enjoyed this quick tutorial on reverse engineering the Facebook API for making a video downloader. If you have any questions/comments/suggestions please put them in the comments below or email me. I will look at reverse engineering a different website for my next post. Follow my blog to stay updated!
Thanks! Have a great day!
Fake Name
Yasoob
In reply to Fake Name